TRK: technically responsible Knowledge
Useful information
- Team members
- Caroline Sinders Cade Diehm Rainbow Unicorn Ian Arduoin Fumat
- Country
- Germany
- Keywords
- design research critical design open source machine learning equitable payment payment structures payment transparency AI transparency
Short Description
TRK is an open source tool for data training and labeling which visualizes wage for transparency.
Detailed Description
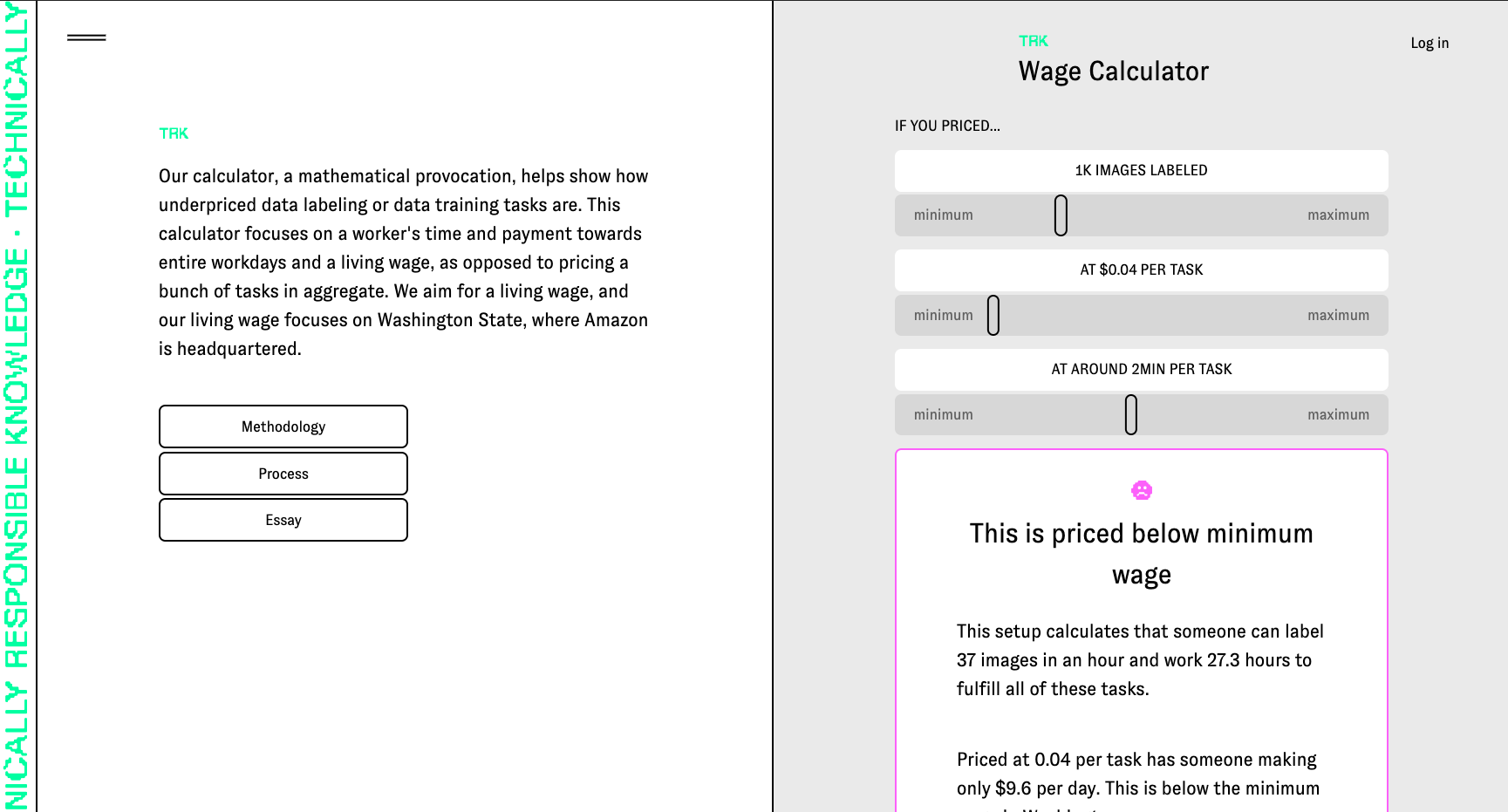
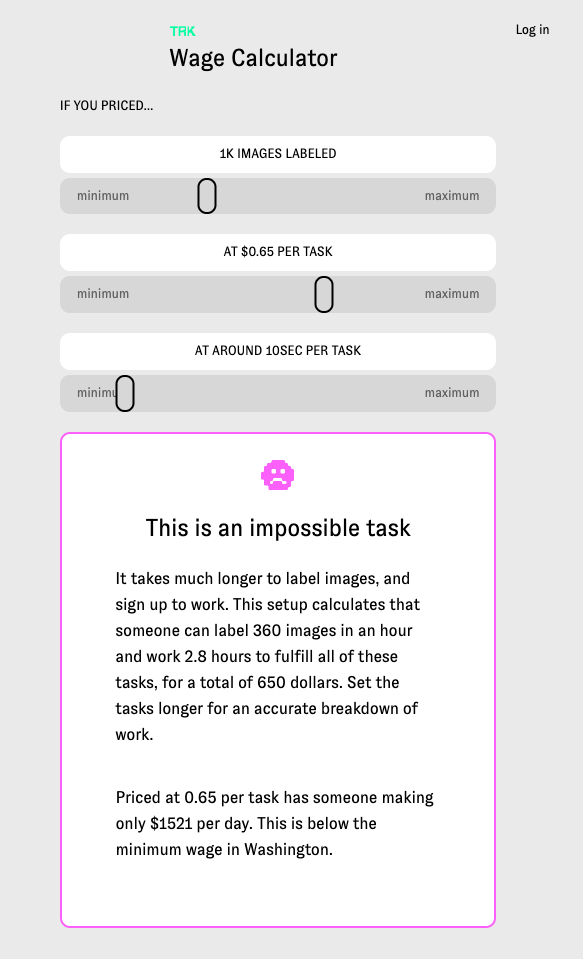
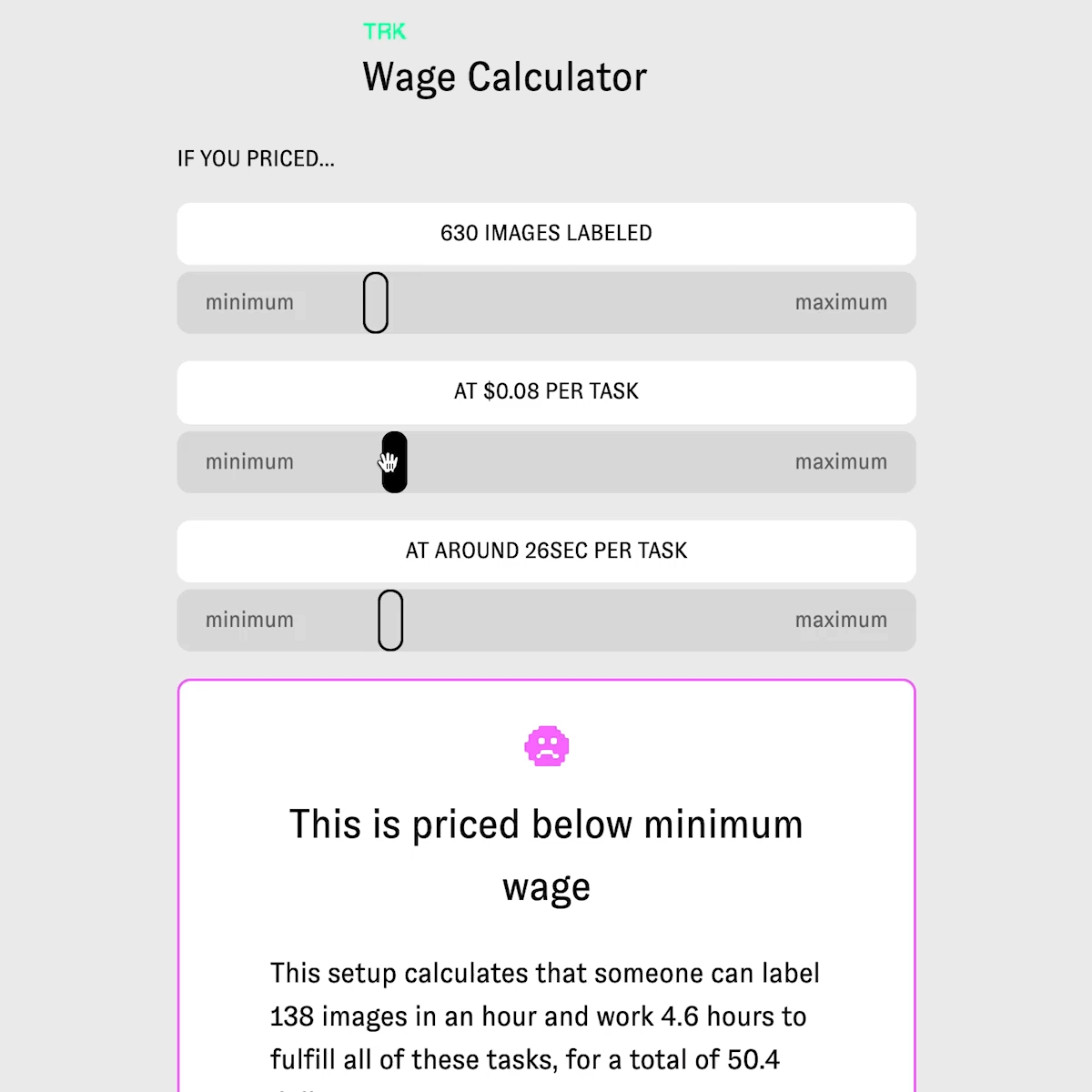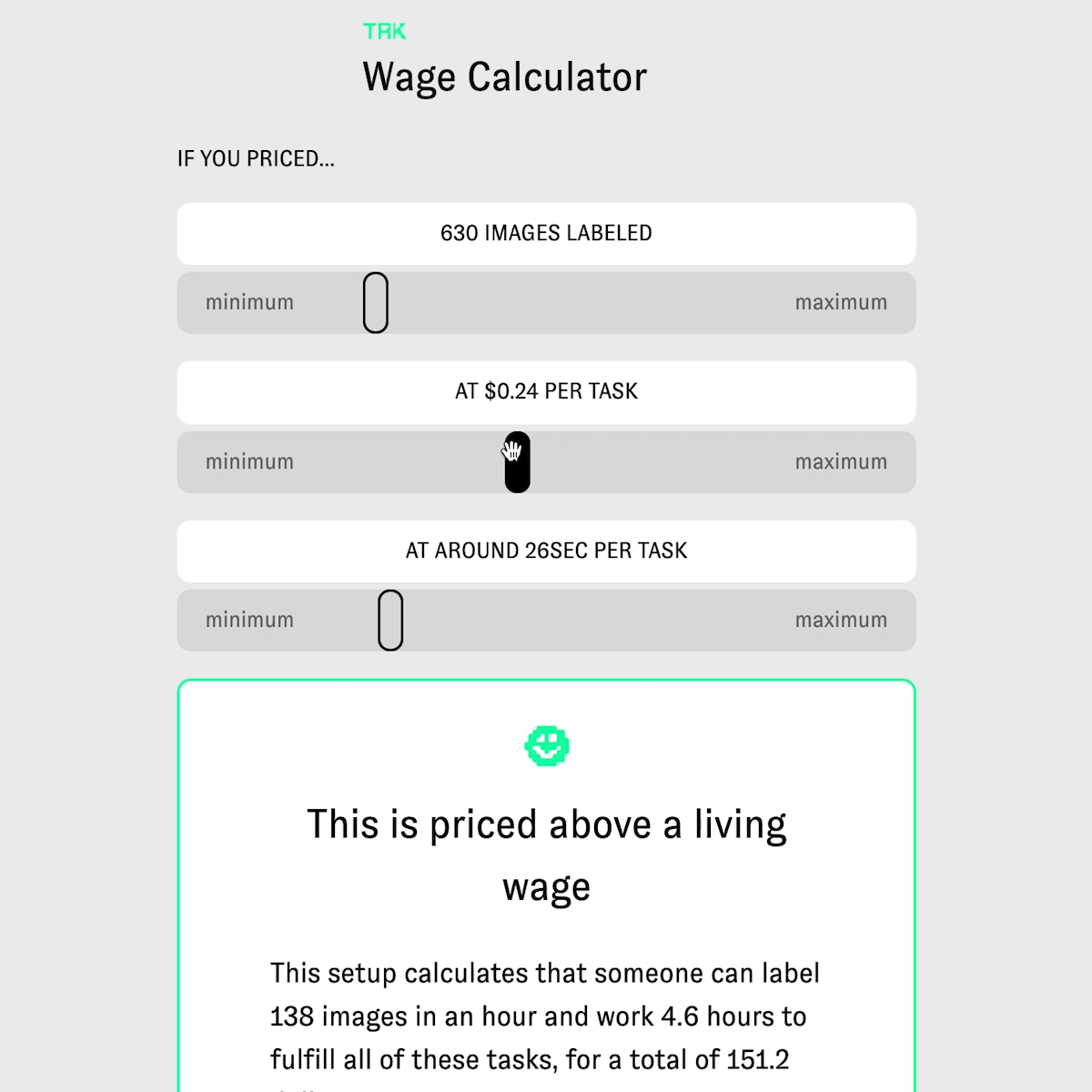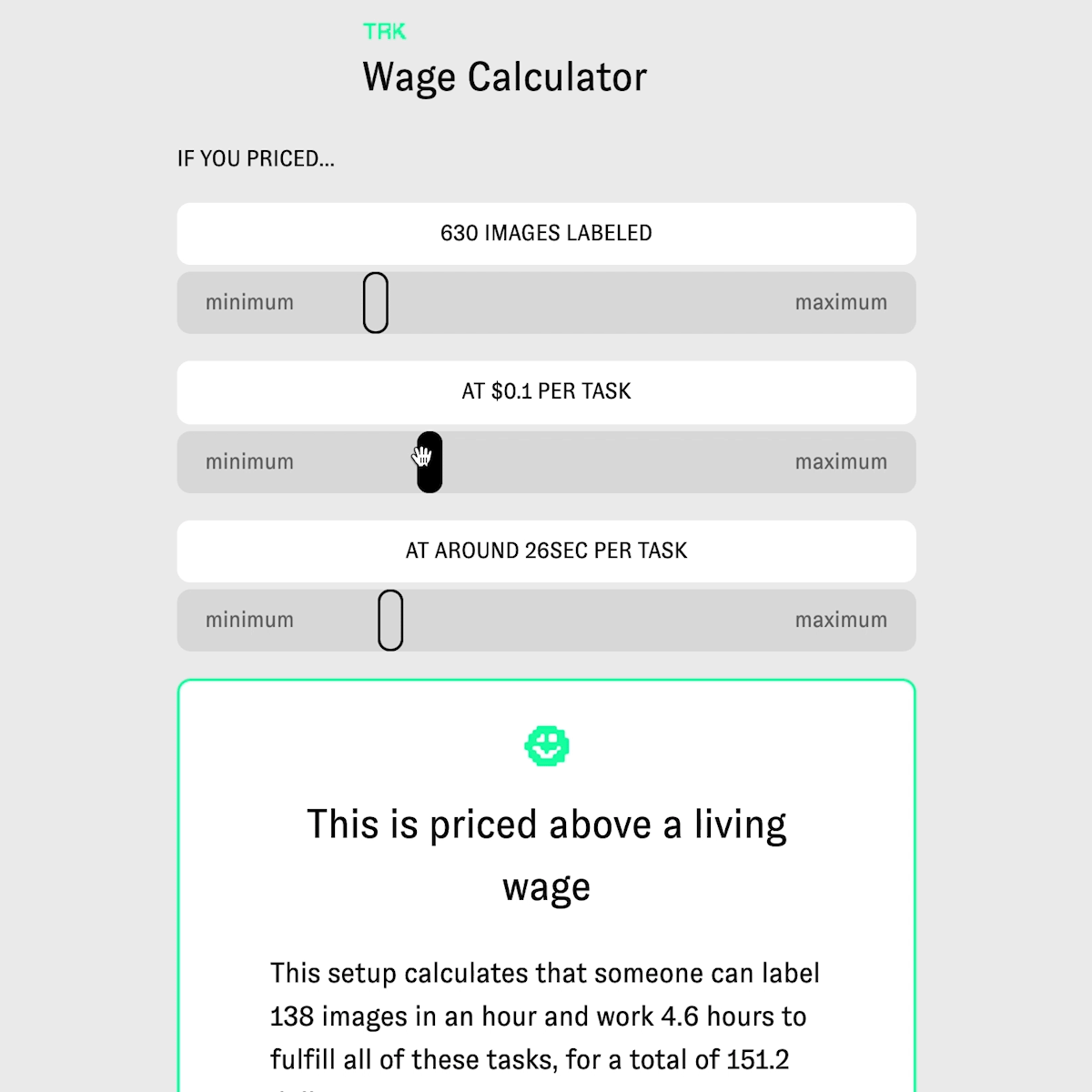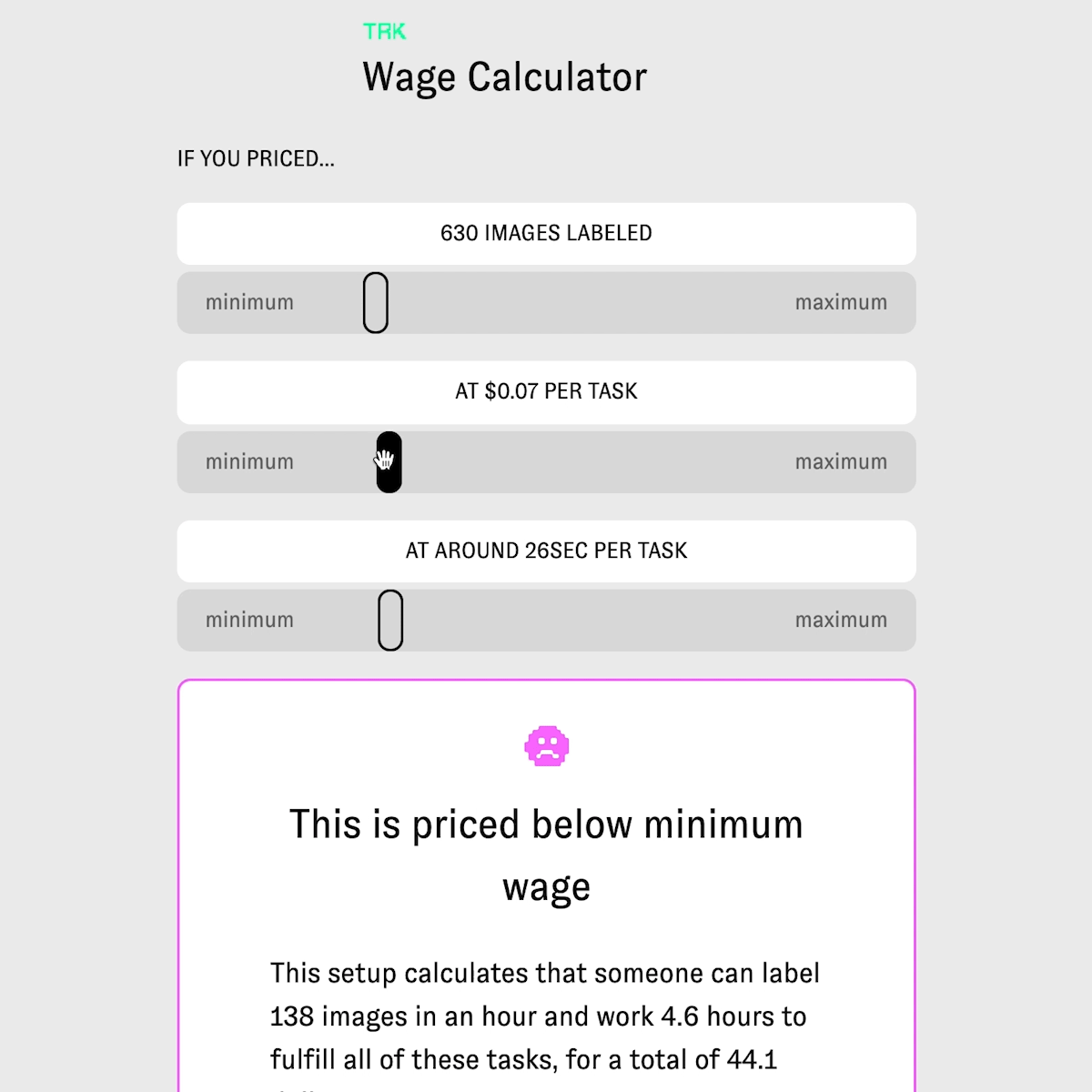
Technically Responsible Knowledge (TRK)is an open source tool for data training and labeling and offers a wage calculator creators that visualizes their tasks for their labelers and pushes creators towards a living wage. calculator focuses on a worker's time and payment towards entire workdays as opposed to pricing tasks in aggregate. TRK focuses on how pricing structures and the invisible nature of gig work, clients underprice, undervalue and misunderstand how tasks are handled in ‘human as a service’ platforms. My team has spent the past year researching and developing this-speaking to gig economy workers and labor researchers. Workers in Mechanical Turk style platforms operate in systems that commoditizes them, leaving them underpaid and poorly treated. This project sheds light on how payment interfaces can function to benefit the worker. Our project provides an open source tool for research labs, artists, and start ups to data train and label, their own data sets and price fairly.
Project Details
- Does your design take social and cultural challenges and human wellbeing into consideration?
Yes, our entire project was focused on understanding pricing, and how tasks are, accidentally or on purpose, priced incorrectly in gig economy and human as a service platforms. What makes TRK innovative and unique is our data labeling tool, which includes demographic information in the data set inspired by data sheets for data sets paper, and the structure of our calculator. Our calculator isn't just calculating a price for tasks- for example, one thousand tasks priced at 4 cents per task which would be 400 dollars. Our calculator, instead, helps show how underpriced data labeling or data training tasks are. This calculator focuses on a worker's time and payment towards entire workdays and a living wage, as opposed to pricing a bunch of tasks in aggregate. Thus, a thousand takes priced at 4 cents per tasks, is suddenly calculated including time to show not only how much these tasks 'cost' but how much time it would take a worker to complete these tasks, and how under (or over) a living wage this worker would earn. We aim for a living wage, and our living wage focuses on Washington State, where Amazon is headquartered. Additionally, creators who start tasks to be labeled are required to describe what is in the data set and workers (the Turker role) are given choices to reject or accept the tasks. Additionally, workers are asked, consensually, if they would like to leave their information in the data set to have an idea of who trained it, where they are from, and when the data set was trained . This project not only tackles wage inequity in AI, but is also creating new methods for injecting transparency into the data set and mode itself.
- Does your design support sustainable production, embodying circular or regenerative design practices?
I describe this a bit above, but it focuses on transparency in data sets used for artificial intelligence and then ways to make micro service tasks more equitable. Our view is that creating sustainable infrastructure and production for machine learning, and then micorservice tasks does involve equitable payment, as well as consensual and ethical transparency into data sets. Equitable payment and transparency are a part of sustainability within technology, as well as creating sustainable systems for workers.
- Does your design use principles of distribution and open source?
Yes, this project was funded by the Mozilla Foundation and is an entirely open source project. Our code is Github under an MIT license, which can be found on our about page. http://trk.network/about
- Does your design promote awareness of responsible design and consumption?
Yes, it does- by focusing on when transparency within data sets and equitable payment for workers/labelers of that data set. Within our tool, the project asks the creator to list what the intentions are of the data set, who they are, what the data is about, and when it was made. For example, if I were making a data set for AI generated poetry, my data set would be on poetry, perhaps English language poetry from the US, Uk, Australia, etc, and it would be made in 2018, with five different people training it, and it's intention would be for AI generated poetry. This information is injected as plaintext at the top of the data model and data set inspired by the paper data sheets for data sets. This way if someone years from now were to access the data set, they would have readable information about the project and why it exists. There is also information that the labelers (turkers) can fill on on who they are, where they're from, etc so there's information about who trained and labeled the data set. This is consensual, so labelers do not have to include this information if they don't want to. This could be useful in data set audits, and future research. Additionally, the wage calculator helps visualize prices creators set and show how under or over a living wage a task is. The key here is that our calculator includes time, which is often left out of calculations or understandings in what makes a 'price' per task fair. If a task takes 1 minute, then if it's priced at 10cents that would be unfair and under a living wage if someone where to do 60 of those tasks. This calculator helps visualize task pricing better with the inclusion of time.
Images